爬虫实战-某电影网站实战
爬虫实战-某电影网站实战
不待前景导入
最近闲来无事,研究上了Python爬虫,先后做了几个小例子,最初的打算是看某些视屏的时候,需要会员看不了,很难受,就想着试试,实战难度可想而知,就我目前而言
- 腾讯视屏
- 爱奇艺
还是不想了,找些电影资源站做一个练手小项目吧
实操
环境准备
- vscode 编辑器
- python 3.7
- Edge
- 一个电影资源站
这里我使用的资源站是星辰影院
第一步
打开网站,找到你想看的电影
我选的康斯坦丁,点击播放他并打开浏览器的开发者工具按键盘上的 f12
点击网络,可以看到以下内容
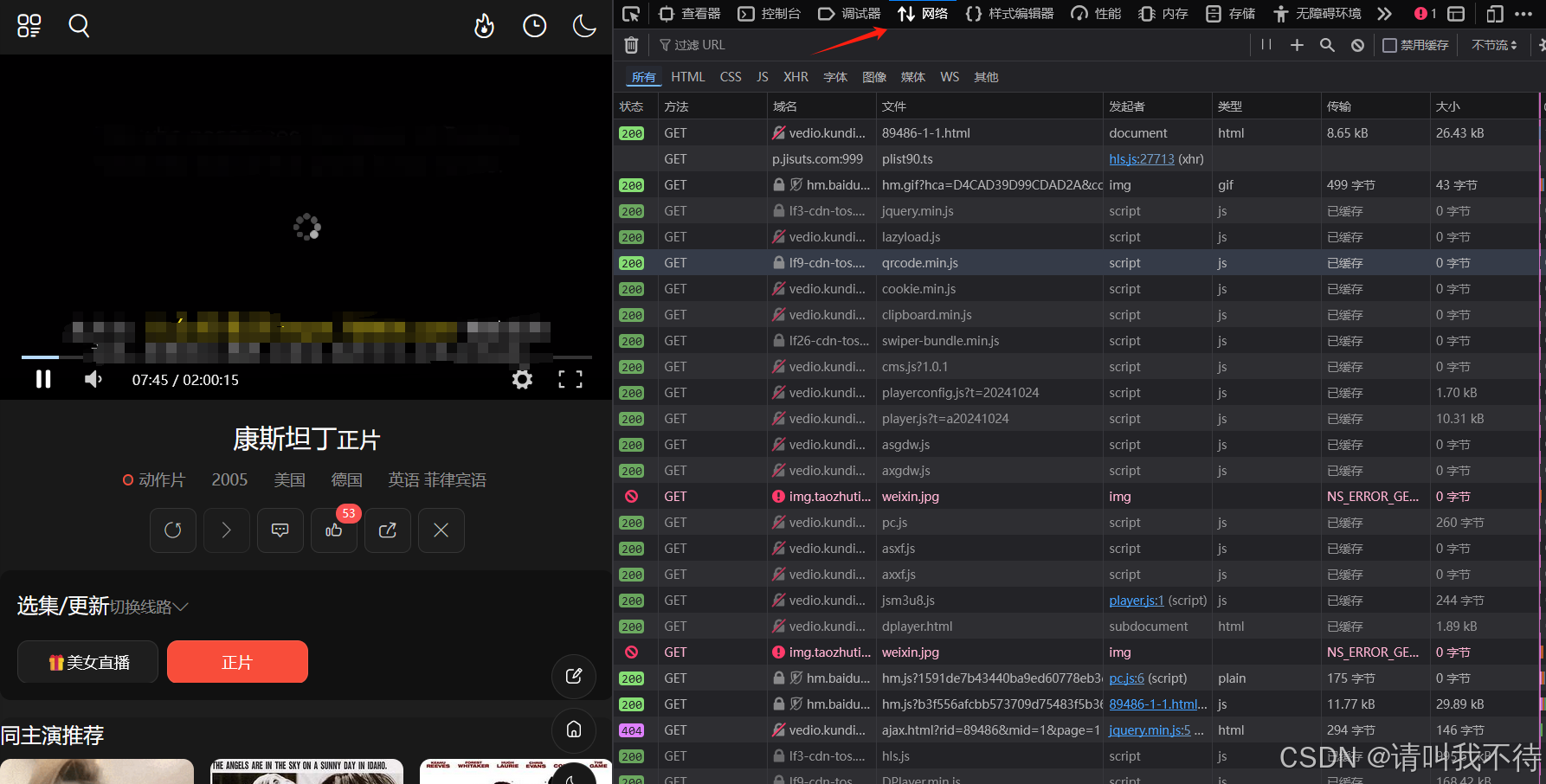
点击媒体
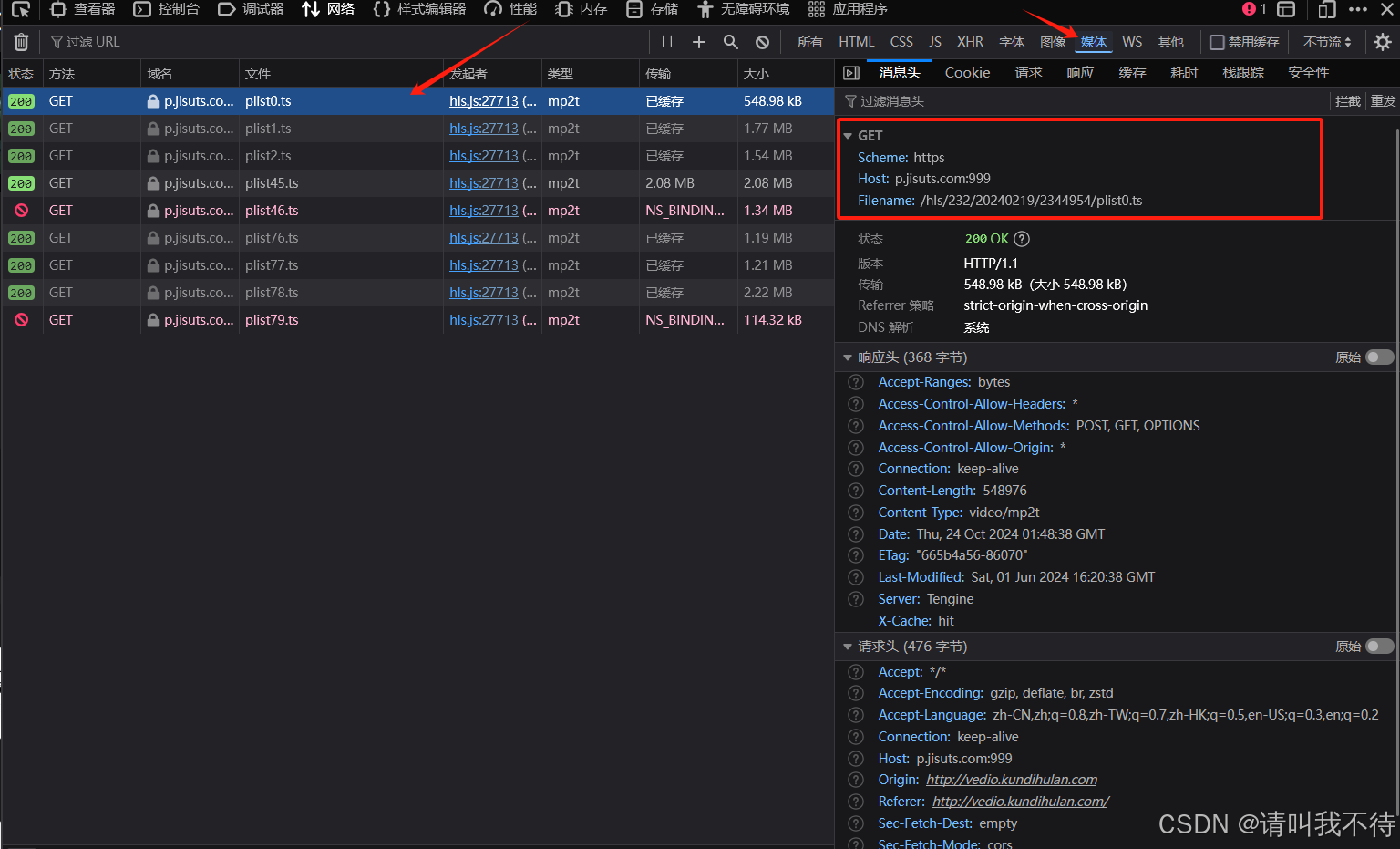
请注意 这里我们看到 电影,在web上时大部分都会选择切割为 多个小的ts文件进行传输,使视屏能更快速的缓存以及边看边缓存,如果我们需要下载这个电影,就是说需要把这些不知道有多少个的ts文件下载下来
1 | 简单分析:随便点开几个切片会发现他们的 Filename 为 |
那么相信大家都看到里面的规律了,在这里呢挨个点击下载到本地也是可以的,不过嘛,我们既然学会了爬虫就大可不必用这种笨方法了不是吗
所以我写了一个简单的小例子
1 | import requests |
这段代码在有些情况下可能不适用,或许有些电影站,只想服务于浏览器用户,那在这里的就没有办法使用这段代码 你需要添加一个请求头
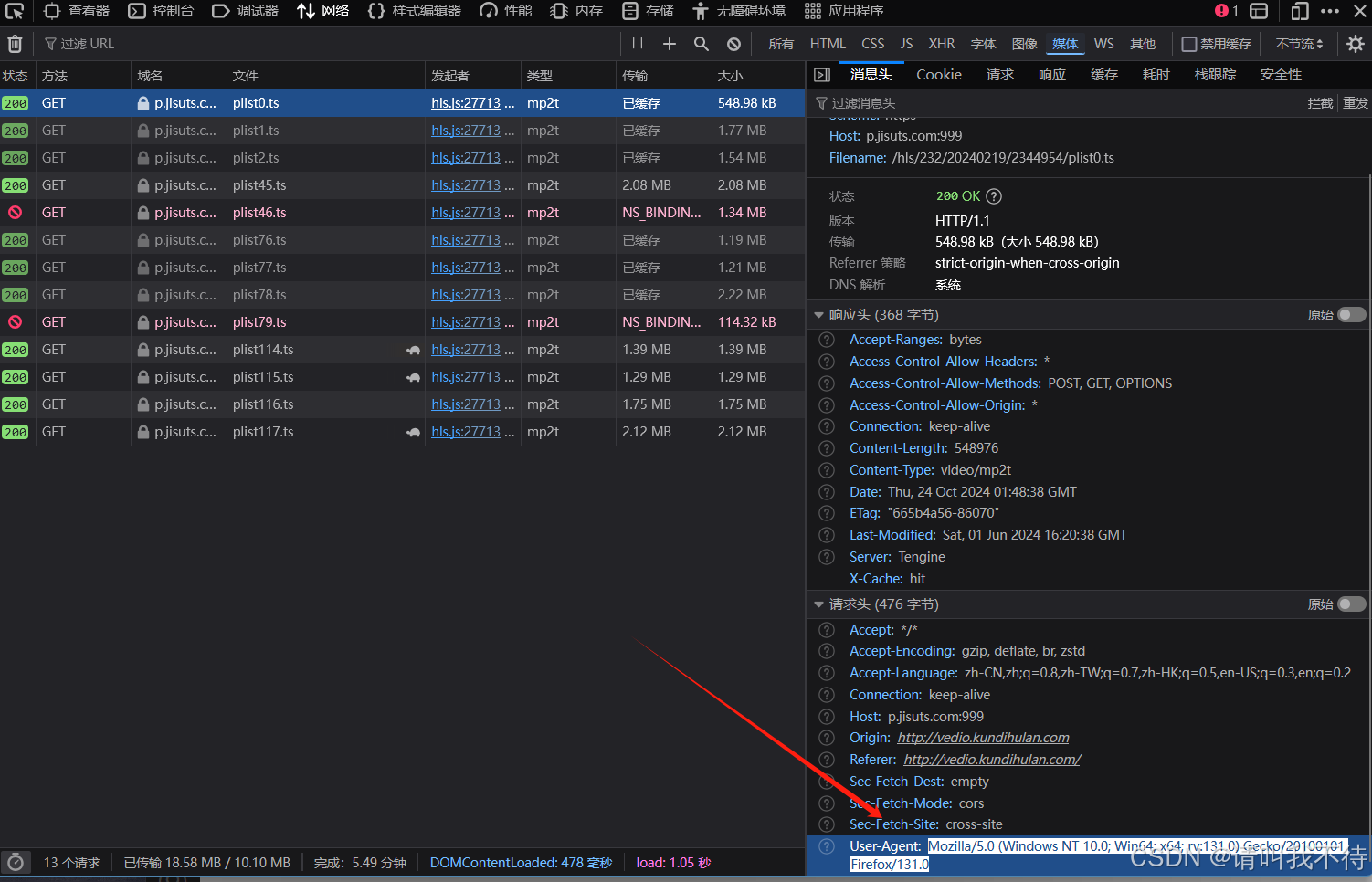
1 | header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:131.0) Gecko/20100101 Firefox/131.0"} |
当他下载完成,可以在你的目录下看到很多ts后缀的文件
很多哈 看的我密集恐惧症要出来了
当然了,现在你把这些文件下载下来了,如果你很幸运,这个文件没有加密,那你可以挨个点开直接看了,就是几十秒换一个很麻烦,所以我们要用到工具
- ffmpeg下载地址
很不幸,这个视屏包加密的,但是有句话叫 三步之内必有解药,我们回到浏览器中,在开发者工具中找两个东西
- m3u8
- key
以这两个为后缀的就是我们的解药
双击把他们下载到ts文件的目录去
右键用记事本或其他工具打开
index.m3u8的内容
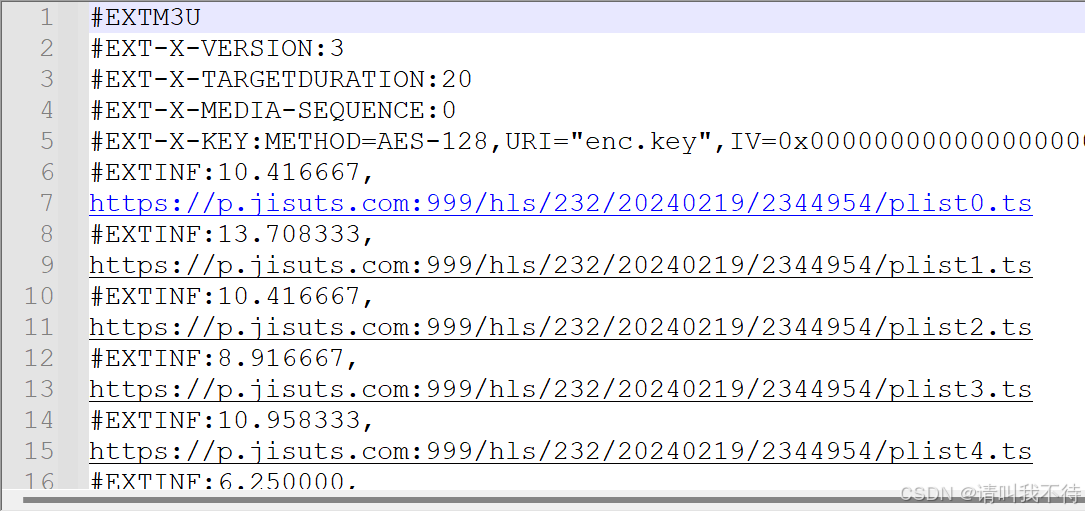
这里的链接就是我们刚才下载文件的链接,那么我们已经把文件下载下来了,所以链接地址也要改成本地的
因为有七百来个ts文件,一个个改要命,我写了个代码来自动去改
1 | ####文件对于爬虫下来的视屏进行文件路径更换#### |
记得把路径改成自己的哦
改好之后呢,我们来把他作为参数文件,在你的ts文件目录中打开cmd
使用ffmpeg 工具
1 | ffmpeg -allowed_extensions ALL -i index.m3u8 -c copy new.mp4 |


喜欢这篇文章的人也看了

评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果